How We Cut Infrastructure Costs by 78% Migrating Python to Go & Rust
Serving AI services should be scalable as the number of requests rise. There are many challenges scaling the software while maintaining best software engineering practices. At Verihubs, most of our services were written in Python. We provide AI-powered identity verification services, with face recognition being one of our core offerings. As we scaled from dozens to thousands of daily requests, our Python-based architecture began showing its limitations.
First version: monolithic service
A monolithic service is easy to develop but tends to have an issue when one component in the system goes down, it can drag the entire service down as well. In most of our services, FastAPI was chosen as the framework as it is easier and faster to develop web services that consume AI models. To maximize our productivity and deliverability in our early stages, beginning with monolithic software was the best choice as the team was still small. Remember, premature optimization is the root of all evil.
As the traffic increased, we still managed to handle the requests by scaling horizontally, multiplying the nodes and distributed the load, which led to high operation costs. Under high load, our face service experienced high memory usage although the load was already distributed across nodes. After several investigations, the service consumed significant memory because it loads a lot of AI models to the memory at initial startup, with sizes ranging from tens to hundreds of megabytes each. Loading models into the memory burdens the whole service because it’s also integrated with the REST API.

The initial version of our face service was very simple, a monolithic python REST API accepted request from users, performed business process, and performed the inference to the models based on the user requests. As the product grew and we had more clients each day, we reached a point where we couldn’t scale it horizontally anymore because it would eat up the cost exponentially.
The docker image size grew to several gigabytes due to copying the huge pytorch models into the image. This led to slow and painful build times during the CI. We used the Gitlab CI and it was incredibly slow to complete the whole pipeline although the stages were pretty standard (test -> check coverage -> build -> post-build). The build itself took 30 minutes to finish.
As the traffic grew aggressively, we needed to scale it horizontally by adding more and more nodes. The costs went up day by day until we realized that we had to do something with the software. Our legacy codebase grew bigger and bigger each sprint.
Why Go and Rust?
Before we decide what to do, we gathered information on what are the problems and how to fix them to become sustainable in the future. The problems are:
- Tightly coupled services
- Unreliable code and memory leaks
- Low performance but high resource usage
- Slow build time and huge image size
It was extremely difficult to trace problems in Python due to a very dynamic type system. The python dynamic objects and garbage collector often caused memory leaks to our programs. The unreliability of the python code cost us a lot and even refactoring the whole code was very painful. So we decided to rewrite it to Go language to address those issues.
Go has proven to have great performance in building web services. We were looking for a language that provides powerful concurrency system, fast build time, and efficient resource usage. Go applications can compile for the target system in a relatively small binary size output. By rewriting our REST API service to Go, we could address the issue of slow build time and huge image size.
Rust is often praised for strong memory efficiency, reliable and strong typing system, no garbage collection, and efficient concurrency. It is a versatile language and easy to understand although many software engineers say it has a steep learning curve. Error handling in Rust has always been easier compared to other programming languages. It does not ship with null so that we never had a null pointer exception. All errors are reported to our log monitoring system and it MUST be handled carefully.
We concluded that rewriting to both Go and Rust addresses all of our concerns: Go’s simplicity and fast compilation for the REST API layer, and Rust’s zero-cost abstractions and memory safety for the performance-critical image processing pipeline.
Separation of concerns
We managed to increase the software reliability by distributing the weight of the resource usage into separate services. Go language is used for the REST API because it has an easier learning curve and the architecture helps us to implement the business processes seamlessly. Rust is used for preprocessing the image before it is going to be passed to the AI models for inference, and the post-process to cook the raw data from the inference result into a more structured format.
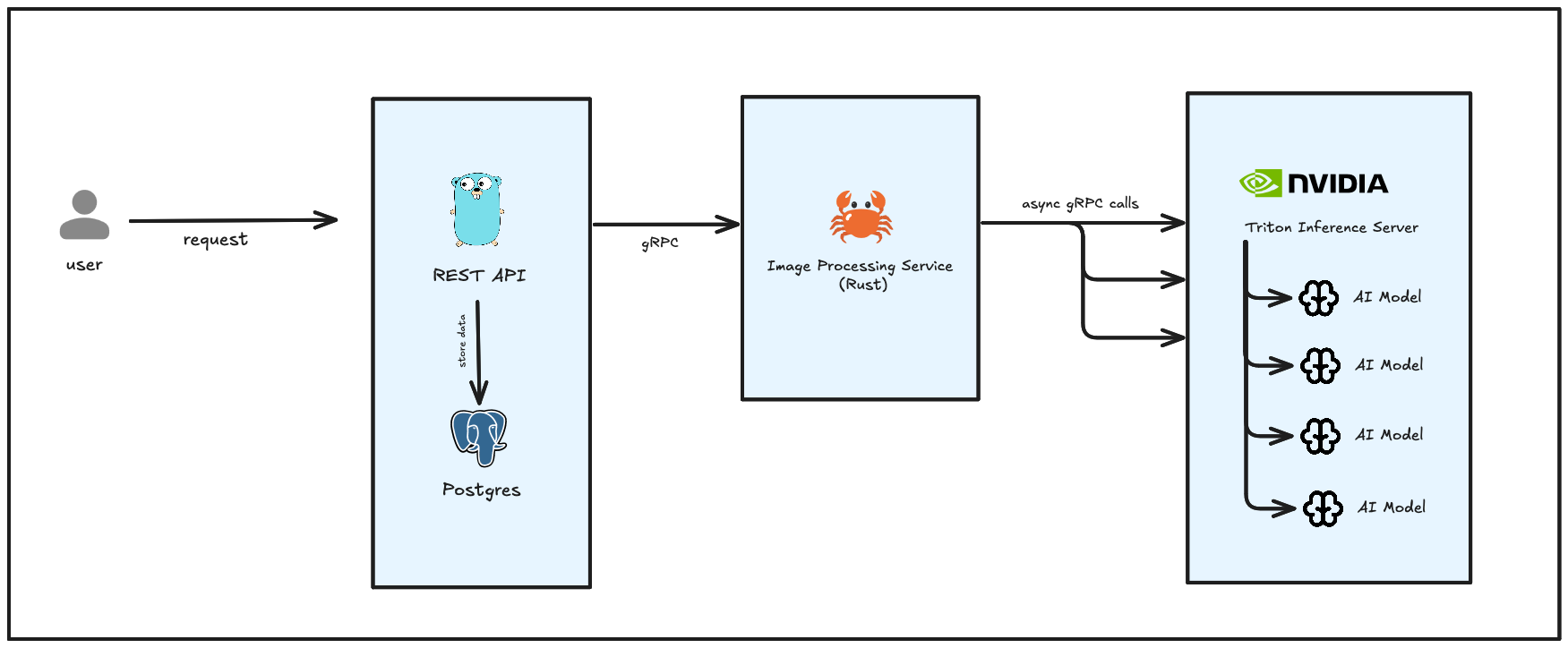
We adopted NVIDIA Triton Inference Server for GPU-heavy model computation. This allows us to isolate the process of the AI processing logic (CPU heavy) and the inference server (GPU heavy). The Rust service focuses on pre and post-processing, while triton focuses on high-throughput model execution and scheduling. This enables independent scaling, we can scale triton nodes without dragging the API along. Other than that, when there is a need to update the model, updating the model is easy with triton, without disturbing the Rust service.
Testing and Deployment Strategy
A/B testing was run before the first deployment to production to ensure the Go and Python codebase has the same output. The requests are rolled out incrementally. In the first deployment, 10% of the requests are routed to the Golang pods, and when everything looks good, we gradually increase it to 30%, then 50%, until finally all requests are routed to the Golang pods. We also implement the blue-green deployment strategy within kubernetes engine, so whenever there’s an issue in the new environment, we can always revert it back immediately.
Improving the flow
Without the garbage collector in Rust, we have full control of the memory usage in our software. For example, in our face liveness detection, we ran through multiple models in one request. In our old python codebase, the original image input is copied to each module to be processed. In each module, there is image preprocessing to make the image suitable to be fed to the model, such as PIL image resizing, OpenCV image transformation, image normalization, and converting it to numpy tensor and then ready to be passed to the AI models. This created huge memory overhead by copying the transformed image and possibly caused memory leaks when the traffic is spiking.
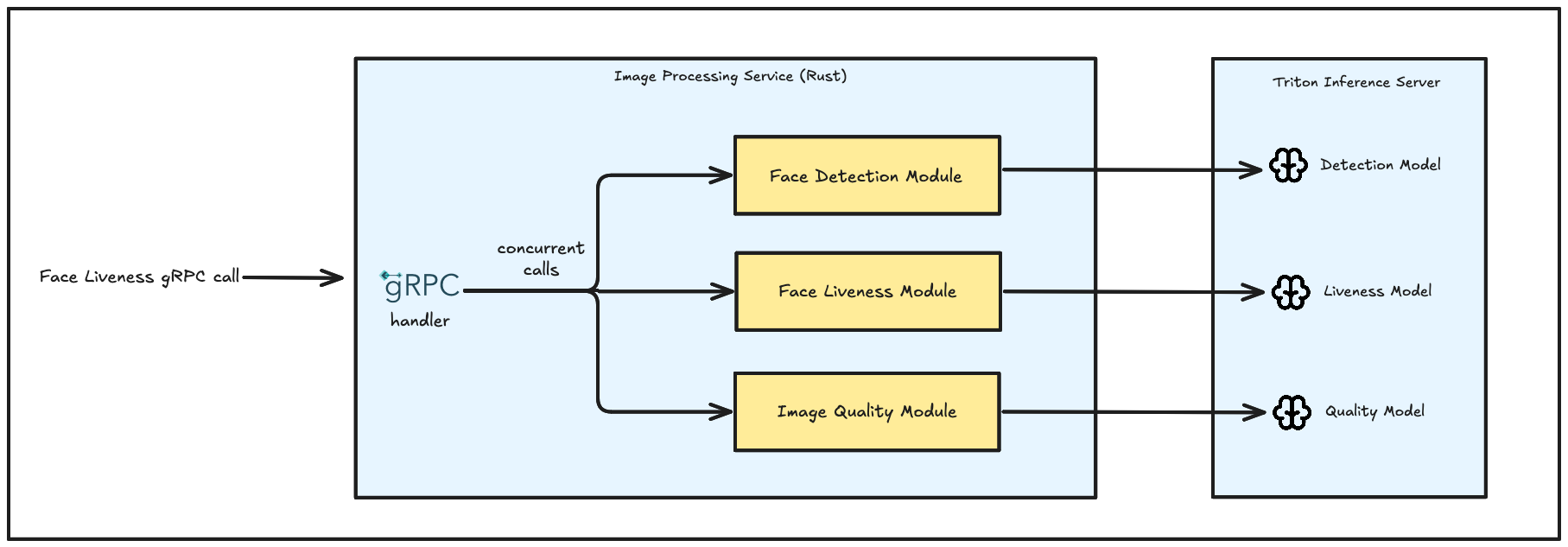
In our optimized Rust codebase, in one call, there is only one original image copy throughout the entire process. We only pass by reference to each module and each module consumes the same image. Our developers need to ensure the lifetime of the image so that the image won’t get dropped while being used by running processes.
The existence of ownership in Rust is really useful as we need to deliberately control who owns the data, who borrows the data, and who is allowed to mutate the data. Async rust might be a bit challenging for beginners, we need to deal with lifetimes, strict ownership, data sharing, and memory safety.
To maximize the performance even further, there’s often an even faster library in Rust for virtually any task. Let’s say you implement image resizing with a standard image crate, there is fast_image_resize which is faster because it uses SIMD instructions, and there’s pic-scale which is even faster!
Results
After several months of running the new Go and Rust codebase, we achieved outstanding results:
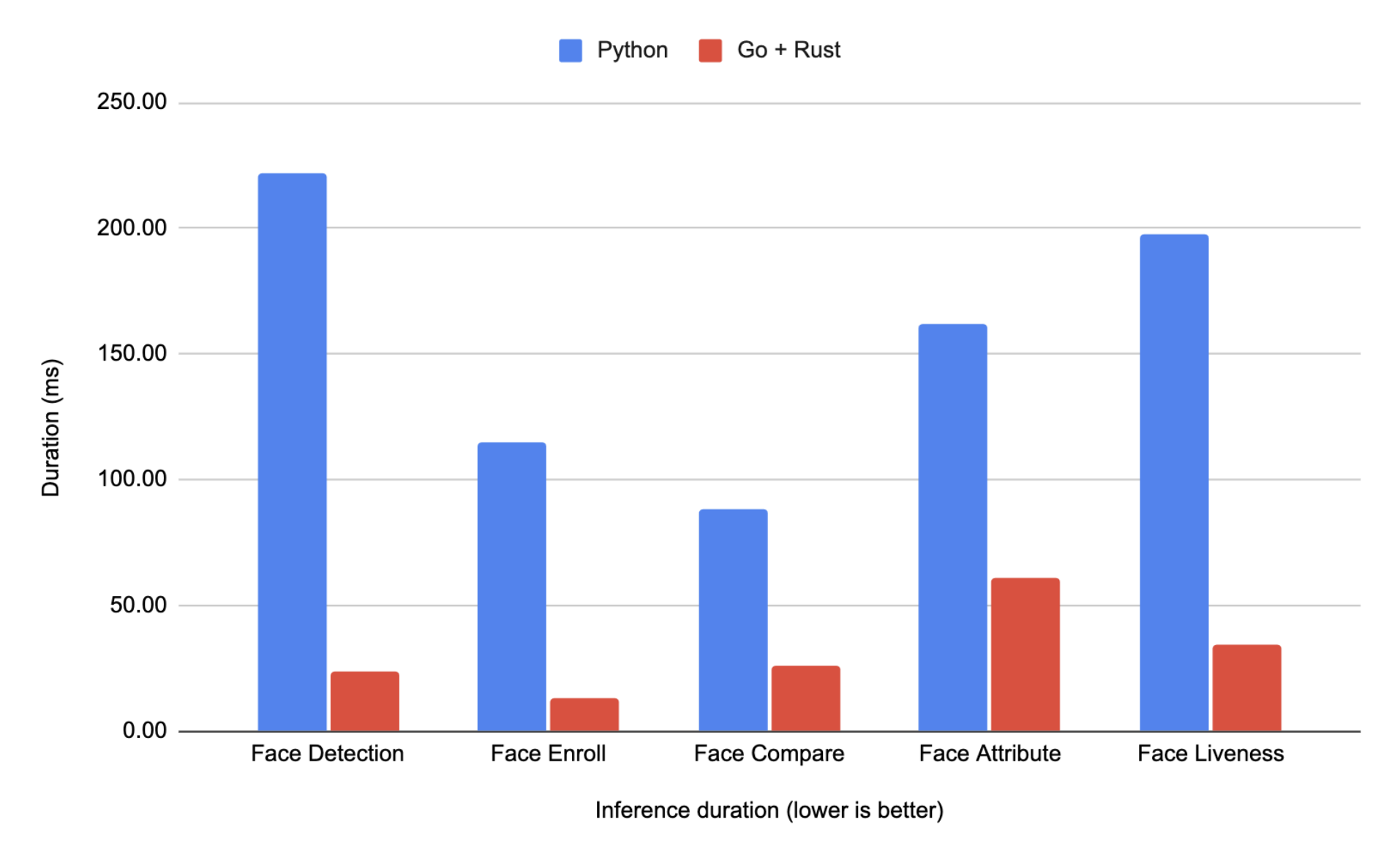
- 50% – 70% faster response times with optimized code and architecture.
- 78% reduction in infrastructure costs by downscaling the infrastructure horizontally (fewer nodes) and vertically (smaller instance types).
- Docker image size reduced significantly from multiple gigabytes to ~500 MB.
- Significantly reduced the build time from 30 minutes to 5 minutes.
- Improved reliability through service separation and enhanced maintainability with clearer separation of concerns.
- Eliminated memory leaks and null pointer exceptions.
Key takeaways
Start simple, optimize when needed. The Python monolithic approach was the right choice initially. It enabled fast development and quick market validation. Only when scaling costs became unsustainable did we invest in the rewrite—a reminder that premature optimization truly is the root of all evil.
Separation of concerns is worth the complexity. Breaking the monolithic service into specialized components (Go API, Rust image processing, Triton inference server) allowed us to scale each layer independently based on its resource needs. CPU-heavy preprocessing can scale separately from GPU-heavy inference, dramatically reducing costs.
Choose the right tool for each job. We didn’t need to pick just one language. Go’s simplicity and fast iteration cycle made it perfect for the REST API layer, while Rust’s zero-cost abstractions and memory safety were invaluable for the performance-critical image processing pipeline. Using both gave us the best of both worlds.
Compile-time guarantees save production headaches. The shift from Python’s dynamic typing to Go and Rust’s static type systems caught entire classes of bugs before deployment. Memory leaks and null pointer exceptions that plagued our Python service simply don’t exist in our current Rust codebase—the compiler prevents them.
Memory control matters at scale. Python’s garbage collector and object copying created massive memory overhead. Rust’s ownership model and explicit lifetime management allowed us to process images by reference instead of copying them through each module, drastically reducing memory footprint. This single optimization enabled us to serve more requests per node.
Results: 78% cost reduction. By migrating from 20+ Python replicas on c6in.2xlarge instances to significantly fewer, more efficient Go and Rust services, we reduced our infrastructure costs by approximately 78%. Build times dropped from 30 minutes to 5 minutes, and we reduced the docker image size from multiple gigabytes to only ~500 MB.
The migration is an investment, not a quick fix. Rewriting working services is expensive and time-consuming. We had to weigh the engineering effort against long-term operational savings. For us, the math worked out—the cost savings and reliability improvements paid back the migration effort within months.